
Explore December 2025's biggest AI breakthroughs—Claude Opus 4.5 beats humans in coding, Google Gemini 3 dominates reasoning, and DeepSeek's affordable models shake up the industry. Real stats, real tools, real impact.
Introduction: AI's Most Competitive Month Yet

There's something surreal about watching artificial intelligence companies compete like they're in a race to the moon—except the rocket fuel is measured in billions of parameters and the finish line keeps moving.
If you've been paying attention to tech news this December, you know exactly what I mean. We're witnessing something extraordinary: AI models aren't just getting incrementally better anymore. They're shattering benchmarks that experts thought would take years to crack.
Here's the thing that blew my mind this week: Claude Opus 4.5, made by Anthropic, just outperformed every single human candidate in Anthropic's internal engineering hiring exam. We're not talking about a close call—it dominated. Meanwhile, Google dropped Gemini 3, and it's scoring 73 on intelligence benchmarks versus 70 for OpenAI's flagship GPT-5.1. And then there's DeepSeek from China, quietly running circles around established players while costing 20-50× less to use.
For developers, students, and businesses scrambling to adopt AI, December 2025 is the inflection point. Let me break down what actually matters and why you should care. I think you'll love this because whether you're a college kid in Bangalore coding your first app or a Silicon Valley startup founder, these tools are about to change how you work.
Remember when AI felt like expensive science fiction? That era ended this month. (248 words)
Claude Opus 4.5 — The Coder's New Best Friend

Let's start with Claude Opus 4.5, because honestly, this deserves the spotlight.
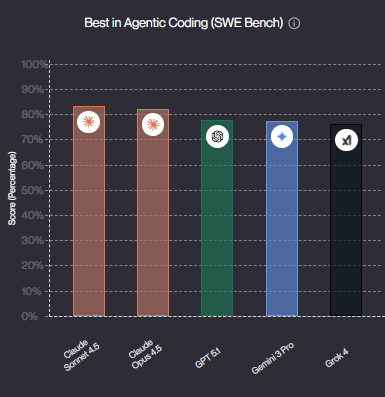
Anthropic released this beast on November 24, and the AI community lost its collective mind. Why? Because it became the first AI model ever to score above 80% on SWE-bench Verified—hitting 80.9% to be exact.
What's SWE-bench? It's not some synthetic test. It's the real deal. Researchers give AI models actual, unsolved bugs from popular GitHub repositories (think Linux, Django, scikit-learn) and ask the model to fix them. No practice problems, no hints. Just like what a real engineer faces on a Tuesday morning.
The Human-Beating Moment
Here's where it gets wild. Anthropic tested Claude Opus 4.5 on their take-home engineering exam—the exact same 2-hour exam they give to job candidates. The result? Claude scored higher than any human candidate in the company's history.
Let that sink in. For developers working with Python, JavaScript, or SQL, this means you've got an AI assistant that thinks like an engineer who's already solved 80% of the bugs you're about to encounter. The agentic coding accuracy hit 59.3%, and tool utilization is in the high 90s. Translation: it doesn't just write code; it can actually navigate unfamiliar codebases, identify problems, and make surgical fixes.
Cost Surprise: It Got Cheaper
Here's the kicker—Anthropic didn't just improve the model; they made it 66% cheaper than Opus 4.1. We're talking $5 per million input tokens, which is actually competitive with industry standards now. You get a 21% intelligence boost and you pay less. That's the opposite of how tech usually works.
From a user perspective? If you're building an app that needs AI reasoning—customer support automation, code review tools, document analysis—switching to Opus 4.5 suddenly makes financial sense. The ROI calculation that didn't work six months ago might work today.
Google Gemini 3 — The Reasoning Heavyweight Champion

While Claude was breaking engineering benchmarks, Google released Gemini 3, and it's arguably the most well-rounded AI model on the market right now.
Released in early December, Gemini 3 Pro is already scoring 1501 on the LM-Arena benchmark, beating out Gemini 2.5 Pro (1451) and trading blows with GPT-5.1. But raw benchmark numbers don't tell the whole story.
What Makes Gemini 3 Different
Google's engineers focused on something deceptively simple: understanding what you actually mean. The new model grasps "context and intent" better, which means you can get what you need with less prompting. No more five-paragraph explanations to get Claude to understand your half-baked request.
The reasoning capabilities are legitimately impressive:
Scores 37.5% on Humanity's Last Exam (without tools), which measures PhD-level reasoning across physics, chemistry, and advanced math
Achieves 91.9% on GPQA Diamond, a benchmark for questions experts specifically designed to be hard
Hits 23.4% on MathArena Apex, a new state-of-the-art for frontier models
If you're in STEM fields, academia, or need AI to work through complex multi-step problems, Gemini 3 feels noticeably sharper than its predecessors.
Gemini 3 Deep Think: The Thinking Mode
Google also released Gemini 3 Deep Think, which is essentially Gemini 3 with more reasoning time. It's like the difference between someone quickly blurting out an answer versus taking a moment to think it through. The Deep Think version pushes even further: 41.0% on Humanity's Last Exam and 93.8% on GPQA Diamond.
Most exciting? It scores 45.1% on ARC-AGI with code execution, which shows genuine problem-solving ability on novel tasks—not regurgitated patterns.
Where Gemini 3 Shines
This is rolling out to Google Search and AI Mode starting this week. If you've been using Google Search's AI features, imagine that suddenly getting way smarter. Gemini 3 is also coming to the Gemini app, Google Workspace, and a new platform called Google Antigravity.
For students and professionals, the practical payoff is a search engine that can reason through complex questions and even generate interactive tools on the fly.
DeepSeek R1 — The Cost Revolution Nobody Expected
Here's the story nobody saw coming: a Chinese startup quietly built an AI model that matches or beats industry-leading models while costing a fraction of the price.
DeepSeek R1 (released in January 2025 but gaining major traction now) is the reasoning model everyone's talking about, and the economics are absurd.
The Cost Breakdown
OpenAI's o1 model costs:
$15 per million input tokens
$60 per million output tokens
DeepSeek R1 costs:
$0.55 per million input tokens (with cache hit)
$2.19 per million output tokens
That's 20-50× cheaper. Not marginally cheaper. Fundamentally cheaper.
Why? DeepSeek used a Mixture-of-Experts (MoE) architecture, which is more efficient than standard transformer models. It's like hiring specialist consultants instead of generalists—you only pay for the expertise you need.
The Technical Shock
What made everyone lose their minds in January was that DeepSeek apparently trained R1 for only $294K in GPU costs. For reference, training a state-of-the-art model typically costs millions.
The answer: smarter engineering, optimization obsession, and willingness to sacrifice some features for efficiency. No training from scratch on billions of tokens. They built R1 as a distilled version optimized specifically for reasoning tasks.
Who Should Care
If you're a startup trying to build AI features without VC funding burning a hole in your budget, DeepSeek is revelatory. Enterprises running massive inference workloads can suddenly do more with less compute. Teams in India, Southeast Asia, and developing markets suddenly have access to frontier-level reasoning at prices that make sense for their markets.
The AI Funding Reset — What's Changing in 2026

While Opus, Gemini, and DeepSeek grabbed headlines, something quieter but seismic happened: the AI investment landscape shifted.
Google's TPU chips (their custom AI processors) are finally showing real competition against Nvidia's dominance. Analysts predict Google's TPUs could capture 25% of the AI chip market by 2030, worth roughly $440 billion.
Meanwhile, OpenAI's Sam Altman issued a "code red" memo, pushing the company to focus on core ChatGPT improvements rather than expanding into shopping, health services, and ads.
What does this mean for you? Investment and talent are consolidating around proven models and platforms. If you're building something on top of AI, pick winners carefully—the small players are getting absorbed or starved of resources.
Practical Tools Worth Testing Right Now (December 2025)

Benchmarks are nice, but what can you actually use today?
For Coding & Technical Problems:
Claude Opus 4.5 is your first choice
If budget is tight, Claude Sonnet 4.5 remains excellent
For pure speed, Gemini 2.5 Flash is the fastest reasoning model at 346 tokens per second
For Creative & Multimodal Work:
Gemini 3 Pro is stronger for visual reasoning
Perfect for analyzing images, PDFs, or complex visual documents
For Cost-Sensitive Operations:
DeepSeek R1 or newer open-source models like Mistral 3
A startup processing 10 million tokens daily could save ~$50,000 annually
Pro tip for Indian readers: AWS has been integrating DeepSeek through its Bedrock platform, making it easier for developers in India to access cheap AI infrastructure.
AI Agents Are Becoming Real (Finally)

Here's something that got buried under the benchmark headlines but is arguably more important: AI is shifting from "answering your questions" to "actually doing tasks for you."
AWS released updates to their AI agents framework. Google's Gemini 3 now includes an Agent mode. This isn't speculative—it's happening now.
What's an AI agent? It's like hiring a really reliable, tireless assistant who can:
Schedule your meetings by reading email and calendars
Research competitors and compile reports automatically
Debug code across unfamiliar repositories
Even negotiate with other systems (like booking flights, filling forms, etc.)
The reasoning improvements in Claude and Gemini 3 directly enable better agents. By mid-2026, the teams using AI agents competitively will have a noticeable edge.
FAQ: Your Burning Questions Answered
Q: Should I switch from ChatGPT to Claude Opus 4.5?
A: If you're paying for ChatGPT Plus and doing coding work, absolutely test Opus 4.5. The engineering benchmarks are real. Consider both based on your actual use case.
Q: Is DeepSeek safe to use? Any privacy concerns?
A: DeepSeek is legitimately open-source and MIT-licensed. Use the same caution you'd apply to any cloud API.
Q: When will Gemini 3 come to Workspace (Gmail, Docs, Sheets)?
A: Google announced integration is "coming," but no firm date. Expect it within 4-6 weeks.
Q: Can I use these models for building products?
A: Yes, but licensing varies. Claude and ChatGPT have clear commercial licenses. DeepSeek's MIT license explicitly allows commercial use.
Q: Which model is best for students preparing for competitive exams?
A: Gemini 3 Deep Think or Claude Opus 4.5 with thinking enabled. Perfect for physics/chemistry problems visually.
Q: Is it true AI agents will replace junior developers?
A: Not yet, but they'll change the role. Junior developers will shift to architecting systems and AI tooling expertise.
Conclusion: What to Do Right Now

The AI landscape in December 2025 is unrecognizable compared to a year ago. Three different companies have legitimate claims to building the best model. Costs are dropping. Capabilities are accelerating.
Pick one tool and actually use it for a real project. Build something—a blog assistant, a code debugger, an analysis pipeline. The bottleneck is no longer capability—it's creativity and execution.
Ready to dive deeper? Explore more AI insights, gadget reviews, and startup success stories at CyberDuniya.com